FUNDAMENTOS DEL APRENDIZAJE SUPERVISADO Y NO SUPERVISADO
- Obtener enlace
- X
- Correo electrónico
- Otras aplicaciones
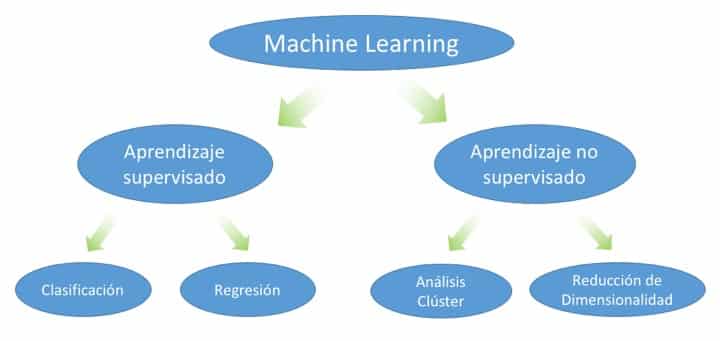
El aprendizaje supervisado y no supervisado son dos enfoques fundamentales en el campo del aprendizaje automático, que es una rama de la inteligencia artificial. Aquí se describen los fundamentos teóricos de ambos:
Aprendizaje Supervisado:
Definición: En el aprendizaje supervisado, el modelo se entrena utilizando un conjunto de datos etiquetados, donde cada ejemplo de entrenamiento consta de una entrada y la correspondiente salida deseada o etiqueta. El objetivo es aprender una función que mapee las entradas a las salidas.
Proceso:
Datos Etiquetados: Se proporciona al modelo un conjunto de datos que contiene ejemplos con entradas y sus correspondientes salidas etiquetadas.
Entrenamiento: El modelo ajusta sus parámetros para minimizar la diferencia entre sus predicciones y las etiquetas reales. Esto se realiza a través de algoritmos de optimización.
Evaluación: Después del entrenamiento, se evalúa la capacidad del modelo para hacer predicciones precisas utilizando un conjunto de datos de prueba que no ha visto antes.
Ejemplos de Aplicaciones:
- Clasificación: Predicción de categorías o clases.
- Regresión: Predicción de valores numéricos.
Ventajas:
- Precisión en la predicción cuando se dispone de datos etiquetados de alta calidad.
Desventajas:
- Dependencia de datos etiquetados.
- Dificultad para manejar datos no etiquetados.
Aprendizaje No Supervisado:
Definición: En el aprendizaje no supervisado, el modelo se entrena con un conjunto de datos no etiquetado, y el objetivo es encontrar patrones, estructuras o representaciones útiles en los datos sin tener información previa sobre las salidas deseadas.
Proceso:
Datos No Etiquetados: El modelo recibe un conjunto de datos sin etiquetas, es decir, solo tiene información de entrada.
Agrupamiento (Clustering) o Reducción de Dimensionalidad: El modelo busca patrones intrínsecos en los datos para agruparlos en categorías (clustering) o reducir su complejidad manteniendo la información esencial (reducción de dimensionalidad).
Ejemplos de Aplicaciones:
- Agrupamiento de documentos.
- Detección de anomalías.
- Reducción de dimensionalidad para visualización.
Ventajas:
- Útil cuando no se dispone de etiquetas para los datos.
- Descubre patrones desconocidos en los datos.
Desventajas:
- Menos control sobre el proceso de aprendizaje.
- La interpretación de los resultados puede ser más compleja.
Ambos enfoques, supervisado y no supervisado, tienen aplicaciones específicas y se seleccionan según la naturaleza y el propósito de los datos disponibles y del problema a resolver. Además, existen enfoques híbridos que combinan elementos de ambos paradigmas, como el aprendizaje semi-supervisado y el aprendizaje por refuerzo. (Chat GPT)
Ejemplo de algoritmo para Aprendizaje supervisado.
En este ejemplo, utilizaremos el algoritmo de Support Vector Machine
para realizar una tarea de clasificación. Supongamos que queremos
clasificar correos electrónicos como "spam" o "no spam" en función de
ciertas características. El conjunto de datos de entrenamiento contiene
ejemplos de correos electrónicos etiquetados como spam o no spam.
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Supongamos que 'features' es una matriz de características y 'labels' son las etiquetas correspondientes.
# Dividir los datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Crear un clasificador SVM con un kernel lineal
clf = svm.SVC(kernel='linear')
# Entrenar el clasificador con datos de entrenamiento
clf.fit(X_train, y_train)
# Realizar predicciones en datos de prueba
predictions = clf.predict(X_test)
# Evaluar la precisión del modelo
accuracy = accuracy_score(y_test, predictions)
print(f'Precisión del modelo: {accuracy}') Ejemplo de Algoritmo de Aprendizaje no supervisado:
K-Means para Agrupamiento (Clustering)
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Supongamos que 'features' es una matriz de características.
# Crear un modelo K-Means con 3 clusters
kmeans = KMeans(n_clusters=3)
# Ajustar el modelo a los datos
kmeans.fit(features)
# Obtener las etiquetas de los clusters asignadas a cada dato
labels = kmeans.labels_
# Visualizar los resultados
plt.scatter(features[:, 0], features[:, 1], c=labels, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', marker='X')
plt.title('Agrupamiento de Datos con K-Means')
plt.show()La elección entre aprendizaje supervisado y no supervisado depende en
gran medida de la naturaleza del problema que se analiza y de la
disponibilidad de datos etiquetados. Aquí hay algunas consideraciones
para decidir:a) La disponibilidad de datos etiquetados, entradas y salidas planificadas, permiten elegir aprendizaje supervisado. b) La estructura compleja de datos no etiquetados, permite agruparlos en grupos
(cluster), y reducir la dimensionalidad para su visualización, permite elegir aprendizaje no supervisado ---------------------------------------------------------------------------------
- Obtener enlace
- X
- Correo electrónico
- Otras aplicaciones


Comentarios
Publicar un comentario